
Odds and Ends
운영체제 6장 CPU 스케줄링 본문
CPU-I/O Burst 사이클
: 프로세스 실행은 CPU 실행과 I/O 대기 사이클로 구성된다. (CPU 버스트로 시작되고 뒤이어 I/O 버스트가 발생함)
- 마지막 CPU 버스트는 또 다른 입출력 버스트가 뒤따르는 대신, 실행을 종료하기 위한 시스템 요청과 함께 끝난다.


CPU 스케줄러
- 준비 큐(ready queue)에 있는 메모리 내의 프로세스 중에서 선택하여, 이들 중 하나에게 CPU를 할당한다. (좋은 프로세스 > CPU를 바쁘게함)
** 준비 큐(ready queue)는 반드시 선입선출 방식의 큐가 아니어도 된다.
CPU 스케줄링을 결정하는 4가지 상황
1. 한 프로세스가 실행 상태에서 대기 상태로 전환될 때 (ex. I/O 요청, 자식 프로세스 종료) > 자진 반납
2. 프로세스가 실행상태에서 준비 완료 상태로 전환될 때 , 디스패치 스케줄에 . 레디큐에 있는 것 중에 하나 골라서줌
(ex. 인터럽트 발생) > 강제 CPU 박탈 (타임아웃에 의해) > ?
3. 프로세스가 대기 상태에서 준비 완료 상태로 전환될 때 (ex. I/O 종료) > 보통 스케줄러 동작 안하는데, (시급한 녀석이면 주긴함. 강제)
4. 프로세스가 종료될 때 > 자진 반납
5. 생성될때 > running과는 상관 없음. (시급하면 주긴함. 강제박탈)
- 상황 1,4에서 스케줄링이 발생한 경우, 비선점(nonpreemptive) or 협조적 스케줄링 방법이라고 한다. 그렇지 않으면, 선점 (preemptive)라고 한다.
- 상황 3,5 는 우선순위에 의해 밀려나 강제 박탈
선점 (preemptive): 뺏을 수 있는 것. 다수 프로세스에 공유 될 때 경쟁조건 초래 가능
비선점 (nonpremmptive) : 뺏을 수 없는 것.
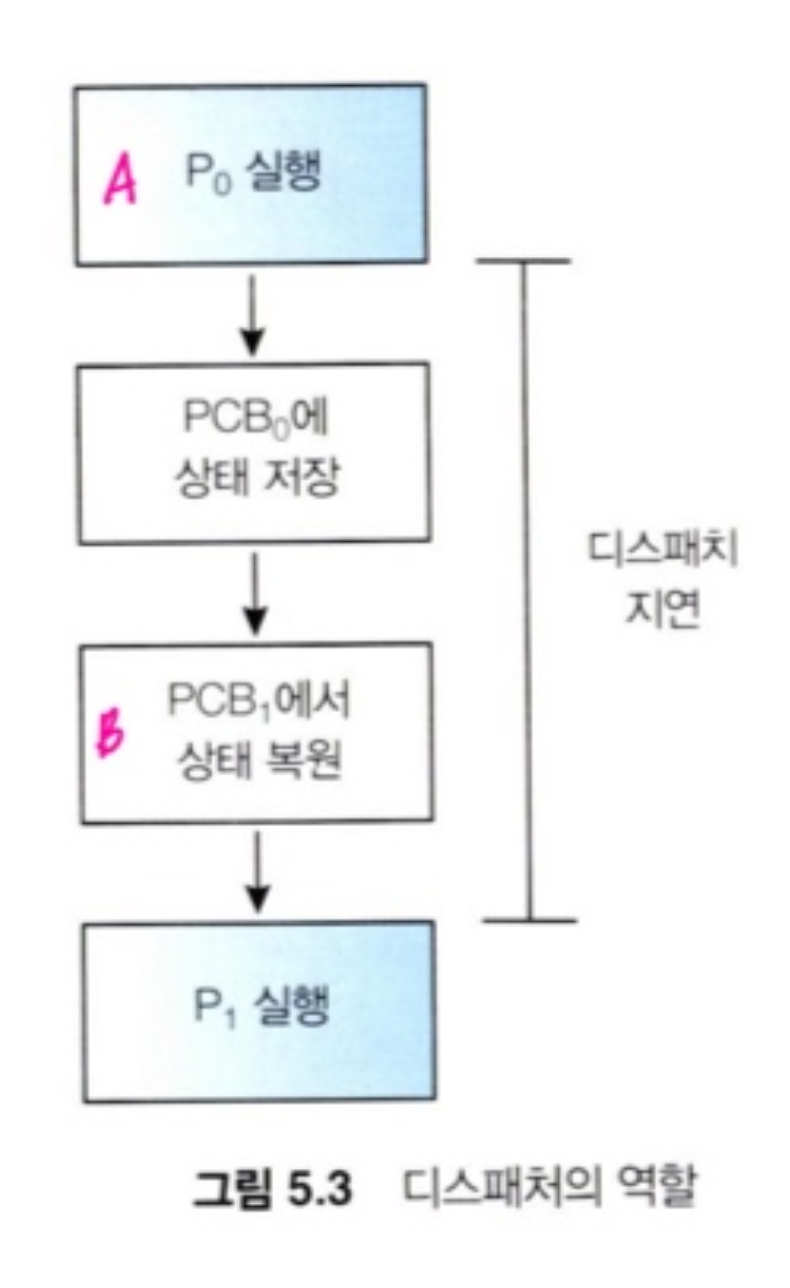
디스패처
: CPU 스케줄러가 선택한 프로세스에 '제어권'을 주는 작업을 함
[역할]
- 한 프로세스에서 다른 프로세스로 문맥 교환 (switching context)
- 사용자 모드로 전환 (user mode)
- 프로그램을 다시 시작하기 위해 적절한 위치로 이동
* 모든 프로세스의 문맥 교환 시 호출되므로, 가능한 최고로 빨리 수행되어야 한다.
* 디스패치 지연 (Dispatch latency) : 디스패처가 하나의 프로세스를 정지하고 다른 프로세스의 수행을 시작하는데까지 소요되는 시간
스케줄링 기준 (성능비교 기준)
MAX
- CPU 이용률(utilization) : 가능하면 CPU를 최대한 바쁘게 유지 (MAX , 바쁠수록 좋음. CPU 활용도 높게)
- 처리량(throughput): 단위 시간당 완료된 프로세스의 개수(=처리된 개수)
MIN
- 총처리 시간(turnaround time) : 특정 프로세스에 드는 시간. 프로세스의 제출(시작) 시간과 완료(종료) 시간의 간격 (대기 , 실행, I/O)
- 대기 시간: 준비 큐에서 대기하면서 보낸 시간의 합. MIN(짧을 수록 좋음)
- 응답 시간: 프로그램을 실행시켰을 때 첫번째 응답이 나올 때까지의 시간
스케줄링 알고리즘
선입 선처리 스케줄링 FCFS (First Come, First Served) > 오는 순서대로!
- 비선점(nonpreemptive)이고 CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당받는다.
- 구현은 선입선출(FIFO) 큐로 쉽게 관리할 수 있다.
* 간트 차트 : 각 프로세스의 시작과 종료 시각을 포함하여 특정 스케줄 기법을 나타내는 막대형 차트



- 선입 선처리 정책하에서 평균 대기시간은 일반적으로 쵯가 아니며, 프로세스 씨피유 버스트 시간이 크게 변할 경우 평균 대기시간도 상당히 변할 수 있다.
호위 효과 Convoy effect
: 짧은 프로세스가 긴 프로세스 뒤에 있으면 지연되는 것. 다른 프로세스들이 하나의 긴 프로세스가 CPU 양도하길 기다리는 것
ex. 큰 느린 트럭 뒤에 작은 승용차들 함께 느리게 가게됨
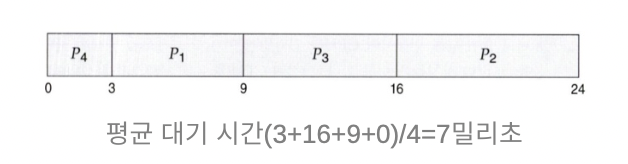
최단 작업 우선 스케줄링 SJF (Shortest Job First)
- 각 프로세스에 다음 CPU 버스트 길이를 연관시킨다.
- CPU가 이용가능해지면, 가장 작은 다음 CPU 버스트를 가진 프로세스에 할당. 즉 작업이 많지 않은 프로세스 먼저 실행
- 동일한 길이의 다음 CPU 버스트를 가지면 둘다 ㄱㅊ, (FCFS 스케줄링 정한다함)
[비선점형]
- SJF 알고리즘이 최적이지만, 다음 CPU 버스트의 길이를 알 방법이 없어서 실제로 구현하기 어려움
- 프로세스들의 대기 시간 평균을 최소로 한다.
- FCFS, RR은 버스트 타임을 몰라도 되지만, SJF는 알아야한다. (버스트 타임이 작은 순으로 순서를 결정하기 때문)
SJF 알고리즘
: 선점형이거나 비선점형일 수 있다. 앞의 프로세스가 실행되는 동안 새로운 프로세스가 준비 큐에 도착하면 선택이 발생한다.
- 새로운 프로세스가 현재 실행되고 있는 프로세스보다 더 짧은 CPU 버스트를 가질 때, 선점형 SJF 알고리즘은 더 짧은 것이 프로세스 선점하고 , 비선점형 SJF 알고리즘은 현재 실행하고 있는 프로세스가 자신의 CPU 버스트를 끝내도록 허용한다.
- 선점형 SJF 알고리즘은 최소 잔여시간 우선 스케줄링이라고 불린다.
비선점형 SJF > 지금 실행하는 프로세스 다 끝나고 버스트 타임 짧은 거 선택

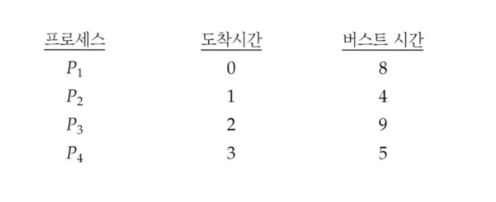
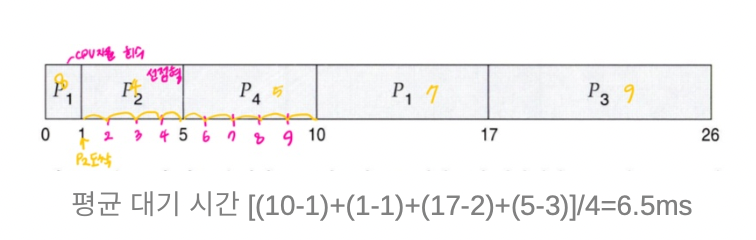
선점형 SJF > 지금 실행하는 프로세스 다 끝나지도 않았는데 버스트 타임 짧은 거 선택
라운드 로빈 스케줄링 RR (Round Robin)
- 작은 단위로 시간을 나눠서 일정하에 정해진 시간만 이용 가능하도록 함. (FCFS는 태스크 하나 전부 끝냄) > 타임 쉐어링에 적합
- FCFS 선입 선처리 스케줄링과 유사하지만, 시스템이 프로세스 사이를 옮겨다닐 수 있도록 선점이 추가됨 (=선점형)
- time - slice, time quantum이라하는 작은 단위의 시간 정의 (10~100밀리초)


- 준비 큐에 n개의 프로세스, 시간 할당량이 q이면 각 프로세스는 최대 q시간 단위로 CPU 시간의 1/n을 얻는다. 각 프로세스는 다음 시간 할당량이 할당될 때까지 (n-1)q 시간 이상 기다리지 않음.
ex. n(프로세스수)=5, q(단위)=20면 각 프로세스는 20ms 로 할당받고, 마지막 프로세는 80초 이상 안기다림.
'운영체제' 카테고리의 다른 글
| 운영체제 교안 Chap 05 스레드 (0) | 2022.10.26 |
|---|---|
| 운영체제 교안 : Chap 04 Process (0) | 2022.10.22 |
| 운영체제 교안 : Chap03 운영체제 구조 (0) | 2022.10.18 |
| 운영체제 교안 Chap02 컴퓨터 구조 (0) | 2022.10.09 |
| 운영체제 교안 Chap01 (0) | 2022.09.26 |



