CS 개념 정리
[자료구조] 트라이(Trie) 개념 정리
Squidward
2022. 10. 9. 23:30
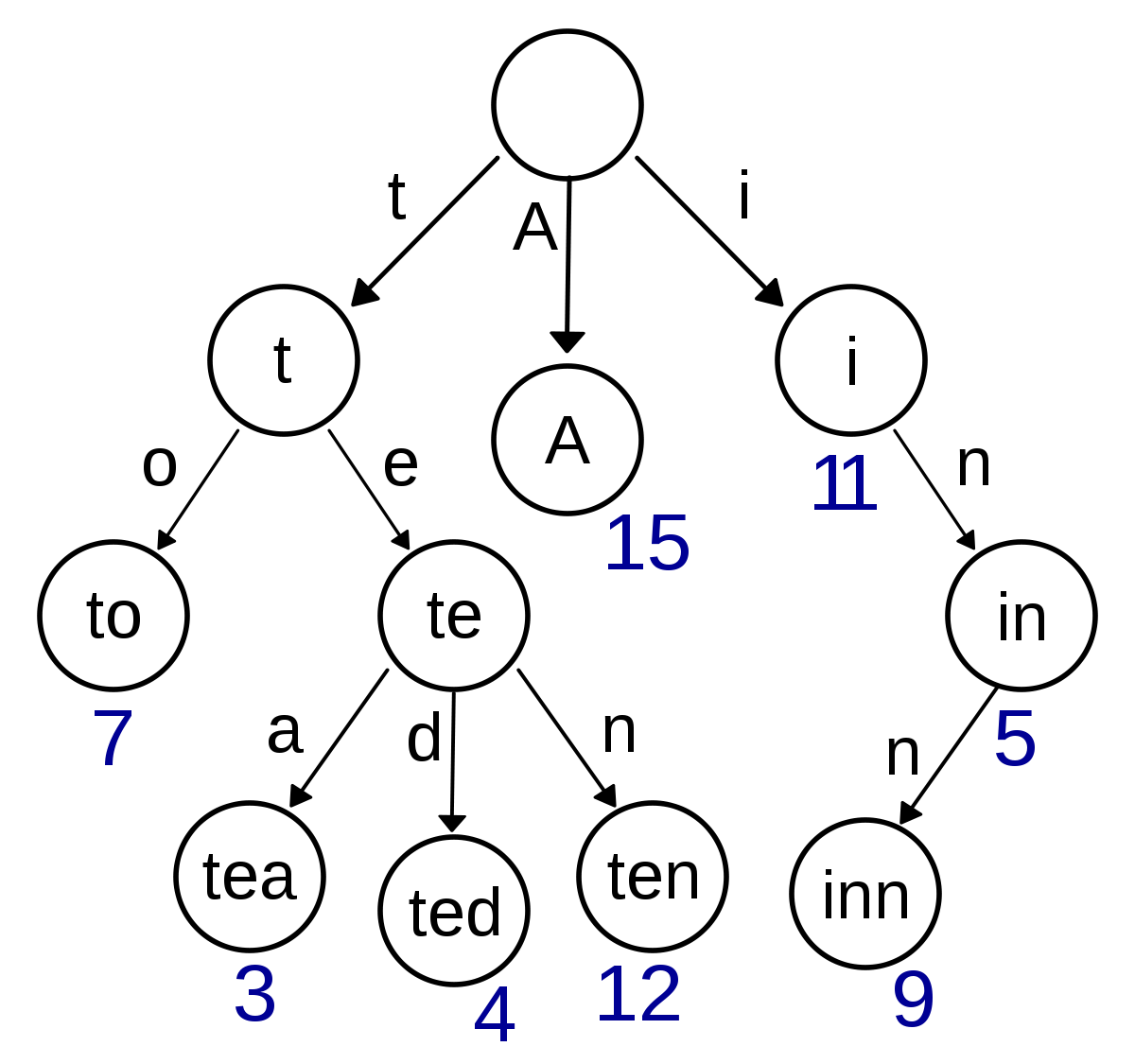
- 트라이(Trie)는 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조이다.
- 우리가 검색할 때 볼 수 있는 자동완성 기능, 사전 검색 등 문자열을 탐색하는데 특화되어있는 자료구조라고 한다.
- 래딕스 트리(radix tree) or 접두사 트리(prefix tree) or 탐색 트리(retrieval tree)라고도 한다. 트라이는 retrieval tree에서 나온 단어이다.
- 예를 들어 'Datastructure'라는 단어를 검색하기 위해서는 제일 먼저 'D'를 찾고, 다음에 'a', 't', ... 의 순서로 찾으면 된다. 이러한 개념을 적용한 것이 트라이(Trie)이다.
트라이(Trie) 장단점
- 트라이(Trie)는 문자열 검색을 빠르게 한다.
- 문자열을 탐색할 때, 하나하나씩 전부 비교하면서 탐색을 하는 것보다 시간 복잡도 측면에서 훨씬 더 효율적이다.
- 각 노드에서 자식들에 대한 포인터들을 배열로 모두 저장하고 있다는 점에서 저장 공간의 크기가 크다는 단점도 있다. (메모리 측면에서 비효율적일 수 있음!)
★ 트라이의 생성 시간 복잡도는 O(MxL), 탐색 시간 복잡도는 O(L)이다.
제일 긴 문자열의 길이를 L이라 하고, 총 문자열들의 수를 M이라 할 때 시간 복잡도는 위와 같다.
생성 시간 복잡도는 모든 문자열 M개를 넣어야하고, M개에 대해서 트라이에 넣는건 가장 긴 문자열 길이인 L만큼 걸리므로 O(MxL)의 시간 복잡도를 가진다. (삽입은 O(L)이다.)
탐색 시간 복잡도는 트리를 제일 깊게 탐색하는 경우는 가장 긴 문자열 길이인 L까지 깊게 들어가는 것이므로 O(L)의 시간 복잡도를 가진다.
728x90